Best SEO Practices for 2024: My Findings from the Semrush Ranking Factors Study
Many in the SEO community are discussing the report on ranking factors for 2024 published by Semrush a few days ago, and I could not pass it by. Being from the Ahrefs camp, I am not an average Semrush enjoyer, but such research is scarce in the SEO field, so it’s worth familiarizing myself with. In this post, I will review and deconstruct the most interesting statements and outcomes of the Semrush study, and present my view on Google’s true ranking factors for 2024.
Is This Really About Google Ranking Factors?
First of all, let me point out that Semrush’s paper is not about ranking factors but on, well, “ranking factors.” Simply put, the report’s title is clickbait: neither Semrush nor any other third party knows in detail how the Google ranking mechanism works (although its conceptual description is well-documented). But Semrush can certainly try to find a correlation between search rankings and different signals. We must remember that correlation does not mean causation. Contrary to popular belief, SEO is mostly unpredictable, so marketers only have one option: try and experiment with different techniques.
What Data is the Semrush 2024 Study Based on?
One reason why Semrush is more than capable of studying the Google search engine is the amount of Google-related data it collects and stores. It is clearly hinted at in the “About” section of the report, which strives to impress the reader with numbers: Semrush databases allegedly store search data on more than 25 billion keywords, 808 million domain profiles, and 43 trillion backlinks. So it is no wonder Semrush tried to decipher Google.
On the flip side, the research did not include an analysis of all the Semrush databases. Instead, they used a sample of ~16,000 keywords with more than 100 monthly searches from the US segment. Here is the list of keywords that were completely filtered out:
- Non-English terms.
- Navigational keywords.
- Branded keywords.
- Adult terms.
- Misspelled and duplicated queries.
The authors then retrieved SERPs with the top 20 links for each keyword, getting around 300,000 positions in total that were used in the research. Some sources like Wikipedia and YouTube were completely omitted to “avoid skewing results.”
What “Ranking Factors” Semrush Study Refers to?
Before diving into the numbers analysis and conclusions, it is worth discussing the “ranking factors” that Semrush analyzed. Their report covers 65 metrics, divided into six categories:
- On-SERP Factors;
- URL & Domain Factors;
- Backlinks Factors;
- User Signals;
- Content Factors;
- User Experience Factors.
Note that many of the metrics used in the study are only utilized on the Semrush platform, thus hardly applicable across the industry. Common examples are Domain Authority calculated according to some of Semrush’s internal formula, and basically all website traffic data, to which Semrush simply has no direct access on a wide scale, so instead provides estimations, which are pretty far from being accurate.
Does this mean we should be negligent about the report? Not at all. I appreciate Semrush’s effort, even if their study is not 100% compliant with reality and the Google algorithm. Plus, there are still a bunch of standard metrics, like the number of backlinks for a URL or a domain, that are more or less based on actual data.
How Correlation is Calculated in Semrush 2024 Study
The authors found how 65 “ranking factors” they picked (I call them parameters or metrics not to confuse them with the term used regarding Google search) linearly correlate with the position in search results.
Each metric has a Spearman correlation coefficient on a scale from -1.0 (absolute negative correlation) to 1.0 (absolute positive correlation). The larger the correlation coefficient, the “stronger” the correlation between two variables, so metrics with more correlation tend to deserve more of a marketer’s attention.
Again, it does not mean that tuning a parameter leads to winning better positions in Google, even if the two are correlated.
Finding #1: A Case for Holistic SEO
One discovery I made after reading a report reassured me of my previous conclusions based on work experience.
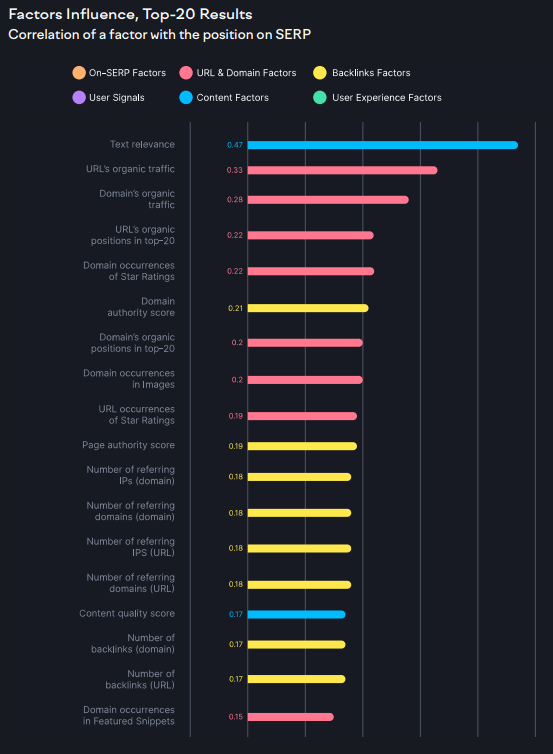
You see, the most correlated parameter in the Semrush study is content relevance with a coefficient of only 0.47, and all other parameters are correlated with positions in SERPs much lower.
For me, this points to two outcomes. First, the selected metrics are too conventional to apply them to the real-life Google algorithm. I’ve already mentioned this: Google does not take most of the parameters picked by Semrush into account. Also, the data being collected or estimated by Semrush is inaccurate, hence the low correlation.
Second, the correlation between the given metrics is non-linear. Essentially, the Google ranking algorithm, a combination of several ranking systems, does not simply check some variables and sort all results by them but rather uses a more sophisticated approach. For instance, it assigns different weights to the various known signals. Don’t forget that a search results page changes dynamically, based on the reevaluation of indexed pages after their recrawl.
Turns out, a marketer willing to achieve given KPIs through SEO should prioritize some signals over others. In a situation of uncertainty, the best strategy would be to focus on different ranking signals at once. As SEO is essentially a “King of the Hill” game, keeping the gap between competitors by ramping up multiple SEO metrics at once sounds like a working plan.
Finding #2: Relevance is King
Any guide on SEO, including Google’s official documentation, will tell you to focus on content quality. But in fact, it is content relevancy that you actually need to care about when optimizing a web page for search in the first place.
I think everyone who saw the report noticed the top-ranking factor per Semrush, the “text relevance,” with a correlation coefficient of 0.47. The second highly correlated metric from the “Content Factors” group is content quality, standing much lower with a coefficient of just 0.17.
Semrush measures content relevance using the same machine learning (ML) model BERT as Google. According to Google, relevance means that content “contains the same keywords as your search query:
Beyond looking at keywords, our systems also analyze if content is relevant to a query in other ways. We also use aggregated and anonymized interaction data to assess whether search results are relevant to queries. We transform that data into signals that help our machine-learned systems better estimate relevance.”
My interpretation: Google likes pages that match the search intent and other top results for a given query the most. Having read many official articles about the search algorithms, I learned that the ability to recognize search intent, i.e., what kind of content a user wants to see in a SERP exactly, is something that Google really likes to brag about, so putting relevance first among ranking signals is anticipated.
On a practical level, this means looking more thoroughly at the links on the first couple of search results’ pages you want to rank your page. I am not calling for plagiarism, but for finding similarities between several top competitors, their text layout, page structure, headings, design, and so on. Thus, you will make sure your page is relevant and will muster high-quality, competitive content for it.
Finding #3: Inbound Traffic and Backlinks
If you look at the general correlation graph, you will instantly spot that the top factors come from only two groups out of the six considered by Semrush. Apart from content relevance, these are parameters connected to either URL or domain traffic and backlinks. Let’s ignore derivative metrics like Domain Authority for a moment and zoom in on those metrics.
Ranking Signals Related to Inbound Organic Traffic
1. The organic traffic to a given URL and the entire domain. In other words, the top 20 is filled with links that have a greater number of visits from search, and with websites having significantly larger audiences than those sites occupying lower places.
2. The number of domain occurrences in the “Images” section. Sites in the top 20 have more (actually, much more) indexed pictures shown in “Images”.
3. URL occurrences in star ratings. Even the paper’s authors seem to admit that star ratings (user reviews of a business), along with images, seem to be the most important SERP feature to look after. These are probably the oldest and most basic features Google has, which makes their domination odd, given how many more features were added to the search engine.
Backlinks-Related Ranking Signals
1. The number of referring IP addresses. This metric has the second highest correlation with rankings compared to other factors from the “Backlinks” group. Semrush explained the reason behind using this parameter in the report: a low number of IP addresses in the backlink profile is a sign of “Black Hat SEO.”
This makes sense on the surface. But Google reps have repeatedly denied the number of referring IPs to be a ranking factor for a link or domain in any way. I think most sites use shared IP addresses (like mine), and many websites, especially big ones, use CDN, potentially increasing the number of referring IPs.
Content at the top of search results is obviously popular, so various sources in different locations refer to it. This does not mean it caused higher rankings.
2. The number of backlinks (both on a page and domain levels).
3. The number of referring domains (both on a page and domain levels).
I think these metrics do not require additional explanation. But let me ponder on causation. The fact: top results in Google’s SERPs have bigger organic traffic and more backlinks. Are these a real reason for higher rankings? Absolutely not. Moreover, I am sure the causation is reversed: these pages got backlinks and traffic after they got to the top. The fact that users only look at the top of the first 1-2 search results’ pages was proven many times, with the click count declining exponentially, starting from the very first position.
Finding #4: Plenty of Secondary Ranking Factors
The report says that only three groups of factors have a meaningful correlation with rankings:
- The content relevance (and quality).
- The volume of inbound organic traffic both to a ranking URL and its domain.
- The number of websites and pages referring to a ranking URL and its domain.
Seemingly, signals from other groups have a too small correlation ratio to even consider their distinctive influence on rankings. Correlation coefficients derived by Semrush suggest that user experience (Core Web Vitals and the Mobile-First principle), and user signals (time on site, etc.), in particular, might not matter for ranking in Google at all.
Is it true? In my opinion, incorrect causation is at play again. If we accept that there is some hierarchy of ranking factors that I mentioned (more details on the subject coming next), Google doesn’t treat all pages equally, giving preference to top SERP links that happen to take most of the organic traffic and backlinks. They might not need to rely on user experience and user signals much, as long as they are at the top. But their competitors can easily leverage these less prioritized areas to dethrone older and slower “kings” from their “hill.” So, the more signals an SEO will cover, the better.
My Theory on Google’s True Ranking Factors
Although the authors of the 2024 Ranking Factors Study wrote a disclaimer about correlation not being equal to causation, in the “Key Learnings” section of the paper, they went straight to interpreting results as if they were indeed ranking factors. Like, suggesting that adding more backlinks and getting more organic traffic will lead to top rankings. I want to warn you against falling for such a fallacy.
The only two metrics from the Semrush 2024 report, in my opinion, that indeed serve as basic ranking factors today, are content relevance and content quality. If we look at how the Google search engine has evolved over time, it starts to make a lot of sense.
The 1990s were the times when the first search engines emerged, however, the issue of indexing content-based data persisted. It is believed that the first efficient page ranking algorithm was developed by Chinese programmer Robin Li around 1996, who called his invention “RankDex.” The system’s basic functionality was link analysis, which enabled sorting websites based on links pointing to them from other sites, that is, backlinks. A similar algorithm called PageRank was created and patented by Larry Page and Sergey Brin in the US and formed the basis of the Google search engine launched in 1998.
At that technological level, backlinks were the only working means of ranking websites, and they probably stayed the primary ranking factor for years to come. However, link spam was (and still is, to some extent) a huge problem.
A ranking factor that can be manipulated is ultimately not beneficial for Google as it disrupts user experience. And it works the same way with keywords, which were another manipulative tool for SEOs in the 2000s. So, Google required better ranking mechanism, and ranking factors.
The rest of the story is well explained by Google Search VP Pandu Nayak in his blog post published in 2022. 2015 became a milestone for Google, with the first AI-based algorithm, RankBrain, implemented in the search engine. According to Nayak, this allowed Google to “understand how words relate to concepts:”
“For example, if you search for “what’s the title of the consumer at the highest level of a food chain,” our systems learn from seeing those words on various pages that the concept of a food chain may have to do with animals, and not human consumers. By understanding and matching these words to their related concepts, RankBrain understands that you’re looking for what’s commonly referred to as an “apex predator.”
Notably, RankBrain is responsible for composing a SERP, choosing the best order for indexed pages.
Nayak went on to tell about other AI-systems that came after RankBrain and became part of the search engine:
- Neural Matching, which “looks at an entire query or page rather than just keywords, developing a better understanding of the underlying concepts represented in them,” thus helping the search engine match queries with pages.
- BERT, a Natural Language Processing (NLP) algorithm within Google, made to understand the context of a query, the meaning of page content in English, and retrieve relevant content from the database for human-readable queries. This is what, for the most part, fuels Large Language Models (LLMs) and their applications today.
- MUM, a more advanced version of BERT, honed to complete the same task but in various languages.
Finally, in 2022, Google introduced the well-known Helpful Content Update, forming the Helpful content system, the main aim of which, in my view, is nothing else than to make more genuine, high-quality content rank higher.
All of the mentioned advancements, along with PageRank, are on the current list of Google’s working ranking systems. Judging by the number of systems with AI and ML components intended to recognize content and search terms on a human level, it is plausible to assume that content is the main criterion (yet not the only one) Google cares about when ranking pages nowadays. It is also the reason relevance is the most correlated with the ranking position in the Semrush 2024 report, not backlinks or organic traffic.
I am not claiming that marketers should neglect all other factors in pushing their websites to the top of Google. Backlinks still matter, as do organic traffic volume, user signals, on-page experience, performance, design, and other signals. But focusing on only one is unlikely to make a good SEO strategy.
Fundamentals of Successful SEO Strategy in 2024
Based on the Semrush report and other details I presented in this article, I have created a few tips I would follow when creating an SEO strategy in 2024.
Content Relevance
Relevance is the true core of an SEO strategy in 2024. Start by analyzing 10-20 pages for the main search term you want to rank for with an article, product, or landing page. Create an outline for your page based on the found similarities.
Content Quality
The first thing after relevance is to make your content original. Don’t just copycat, and don’t build your text around keywords. Try to go above average: add more useful details resonating with your target audience that others from the top 20 don’t have. Enrich your content with original images, infographics, stats, and numbers. Make sure a page is well-structured. High-quality content is a “trick” that always worked for me. As I already said, this is what Google has been wanting recently.
Holistic Approach
Tackling as many ranking signals as possible is still the key to retaining positions in search results and outplaying competitors. What signals to address exactly is something that usually depends on your professional background and capabilities: one might know how to improve a backlink profile fast, while another might want to focus on reaching Core Web Vitals. Ultimately, you would like to aim for the signals that are the weakest for your or your competitors’ website.
Keywords Usage
After you have finished with copywriting, seek as many related search terms as you can. Ideally, take the whole cluster of keywords for your parent term and ensure they are present in your copy at least once. Keywords should feel natural and not diminish the quality. Overall, they are key to enhancing your page’s visibility and ensuring content relevance.
Excel Among Equals
Use the details that determine your page’s relevance and distinguish it from other results in its meta title and description at the same time. This would be critical for CTR, which adds to the organic traffic volume, a crucial ranking factor. Balancing uniqueness with relevance is what really matters for SEO in 2024.
Closing Thoughts
I am confident that SEO in 2024 will continue to shift towards originality, and Google will continue favoring genuine content capable of attracting and engaging large audiences. What is exciting is that this trend is completely in line with the development of generative AI. Yes, ChatGPT can produce highly relevant content. But it is literally the average version of all information on the topic. Adding at least the “hand-made” layer on top of it is what will drive the competition.